Fluentd: General Note
Sep 17, 2019
4 mins read
Fluentd is a powerful open-source logging tool that has flexible functionalities.
The overall fluentd’s workflow:
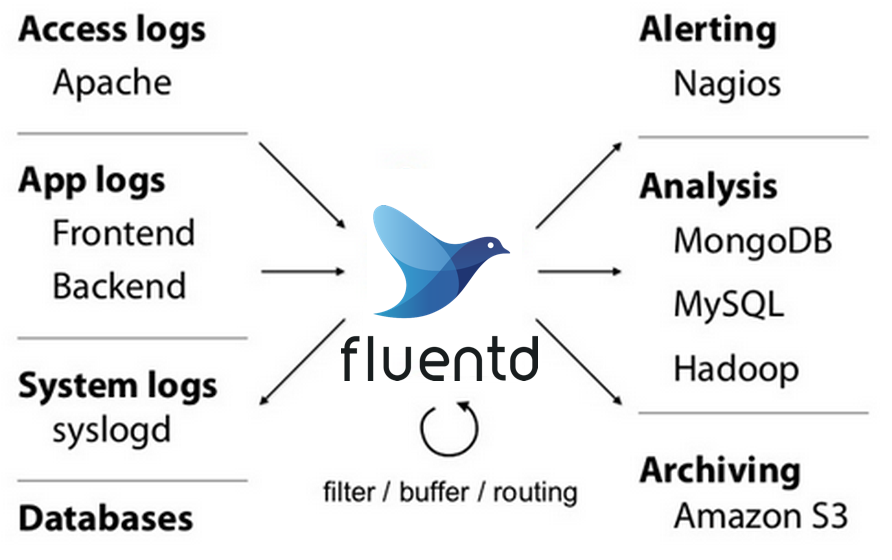
The logic behinds fluentd is quite simple:
- There are sources of data, such as file, http traffic, etc., you tell fluentd what to listen.
- You define rules that specify what event should be logged.
- You define how the event should be processed.
The simplified structure of fluentd’s configuration file can reflect the logic above:
<source>
1. You tell fluentd what to listen.
</source>
<filter>
2. You tell fluentd what should be logged.
</filter>
<match>
3. You tell fluentd what to do with the data.
</match>
Directive
<source>, the data source.<filter tag>, filter the data withtag.<match tag>, capture and store the data withtag.
Event
A fluentd event consists of:
tag, where an event comes from.time.record, log content, JSON object.
Plugins
A plugin in the context of fluentd is a kind of logic of operation. There are plenty of kinds of frequently used plugins.
1. Input plugin
Input plugin creates a thread, socket, and listening socket, it’s used with the <source> directive that specify what kind of source that should be listen.
tail: tailing a target file as source, thepathfield specifies the file path to be tail.
<source>
@type tail
path /var/log/xxx.log
tag tag.xxx
</source>
http: listening http traffic
<source>
@type http
port 9880
bind 0.0.0.0
body_size_limit 32m
keepalive_timeout 10s
</source>
2. Parser plugin
Used with <parse> directive, parse the specific type incoming data into the following format:
time:
<timestamp> (<date time>)
record:
<json object>
For example:
time:
1362020400 (2013-02-28 12:00:00 +0900)
record:
{
"name" : "alice",
"title": "engineer",
"id" : 1
}
You can use this directive if you know the data format in advance.
e.g. 1
If the input data is in json format, you can use json parser plugin to parse it:
<parse>
@type json
json_parser json
</parse>
Incoming event:
{"time":1362020400,"host":"192.168.0.1","size":777,"method":"PUT"}
Output:
time:
1362020400 (2013-02-28 12:00:00 +0900)
record:
{
"host" : "192.168.0.1",
"size" : 777,
"method": "PUT",
}
e.g. 2
If your data source is nginx’s log, you can use nginx parser plugin.
Incoming event:
127.0.0.1 192.168.0.1 - [28/Feb/2013:12:00:00 +0900] "GET / HTTP/1.1" 200 777 "-" "Opera/12.0" -
Output:
time:
1362020400 (28/Feb/2013:12:00:00 +0900)
record:
{
"remote" : "127.0.0.1",
"host" : "192.168.0.1",
"user" : "-",
"method" : "GET",
"path" : "/",
"code" : "200",
"size" : "777",
"referer" : "-",
"agent" : "Opera/12.0",
"http_x_forwarded_for": "-"
}
You will need to put the <parser> nested inside <source> or <filter>
As a bigger example, if you have a /var/log/xxx.log file that you know in advance every line is a json object, you can use json parser, and right inside the <source> directive.
<source>
@type tail
@id xxx_log
path /var/log/xxx.log
tag example.xxx
read_from_head true
<parse>
@type json
json_parser json
timezone -08:00 # GMT+8
time_format %Y-%m-%dT%H:%M:%S.%NZ
</parse>
</source>
<match example.xxx>
...decide what to do with the parsed data
</match>
3. Formatter plugin
Used with <format> directive, transform the data into specific type.
-
out_fileformat each record intotime[delimiter]tag[delimiter]record\n. -
json
<format>
@type json
json_parser json
</format>
You will need to put the <format> nested inside <match> just like <parser>.
4. Filter plugin
grepDecides what data should be matched based on given rules.
<filter foo.bar>
@type grep
<exclude>
key message
pattern /uncool/
</exclude>
</filter>
The above configuration will remove the events that message field contains uncool.
record_transformerAdd custom record.
<filter foo.bar>
@type record_transformer
<record>
hostname "#{Socket.gethostname}"
</record>
</filter>
5. Output plugin
Output plugin are used with <match> directive.
file: output logs to file inpath.
<match pattern>
@type file
path /var/log/fluent/myapp
compress gzip
<buffer>
timekey 1d
timekey_use_utc true
timekey_wait 10m
</buffer>
</match>
The <buffer> buffer the data into file or memory (default to be specified by output plugin)
// save buffer to file:
<buffer>
@type file
</buffer>
// or memory:
<buffer>
@type memory
</buffer>
out_elasticsearch: output to Elasticsearch.
<match my.logs>
@type elasticsearch
host localhost
port 9200
logstash_format true
</match>
Example
Listening for HTTP requests on port 8888:
<source>
@type http
port 8888
bind 0.0.0.0
</source>
if the in coming event has a Tag equals to test.cycle, the rule will be matched:
<match test.cycle>
@type stdout
</match>
$ curl -i -X POST -d 'json={"action":"login","user":2}' http://localhost:8888/test.cycle
HTTP/1.1 200 OK
Content-type: text/plain
Connection: Keep-Alive
Content-length: 0
Integrate fluentd with k8s
For Kubernetes, a DaemonSet ensures that all (or some) nodes run a copy of a pod. In order to solve log collection we are going to implement a Fluentd DaemonSet.
Sharing is caring!